
The term observability is not new in the industry. It has seen several changes and evolution to the point that it is now. Several companies have invested funds that run somewhere between thousands to millions and even billions for the huge tech giants.
One of the benefits is that it is supposed to reduce operational costs/stay within the budget but this is not always the case, the associated cost could also rise as there is a possibility that your team spends a lot of time trying to get it to work, you’re not storing the logs/data ingested properly or you’re using tools that are too cumbersome for your actual use-case/business need. This could lead to a cost that is way over the budget.
As systems continue to become more complex and generate more data, the cost of tools and infrastructure is likely to continue to rise. Teams must carefully weigh the benefits of observability against the costs, and find ways to balance the need for observability with the need to maintain developer productivity and costs.
It need not be that expensive when wired up properly. Although this post isn’t to explain observability, but rather to shed more light on best practices to follow in order to cut down the cost of observability in your business, I still feel the need to briefly explain what it is and the benefits it can bring to your organization/business in case you are not using it already.
What is observability?
It refers to the ability to understand and diagnose the behavior of a system based on its internal state and output. In the context of the tech industry, observability refers to the ability to understand the behavior and performance of complex systems, such as microservices and distributed systems. It helps provide insight that helps you resolve issues and achieve increased uptime for your users in the long run.
It involves collecting data and telemetry from various components, including application code, infrastructure, and network activity. This data, which is also known as observability data, is then processed and analyzed using specialized tools and techniques to gain insights into how the system is functioning and to identify any issues or anomalies.
The goal of observability is to provide visibility into the performance and behavior in real-time, allowing developers and operations teams to quickly identify and address any issues that may arise. This is particularly important in modern systems, which are often highly distributed and complex, making it difficult to diagnose and fix issues without the use of the right tools.
There is a high chance that you are already monitoring your infrastructure using a particular tool but this might not be observability. It might sound confusing but there is indeed a difference between both.

The source link for the image above is here
Difference between monitoring and observability
While both are related concepts, the latter provides a more comprehensive and proactive approach to managing and understanding complex systems. By providing real-time insights into behavior, observability can help teams identify and address issues more quickly and effectively, improving overall system reliability and user experience. There are some key differences between them:
Focus: Monitoring typically focuses on collecting and analyzing predefined metrics and logs, such as CPU usage, memory usage, and error rates. In contrast, the other focuses on providing a more holistic view of behavior, allowing teams to identify and diagnose issues that may not be captured by predefined metrics.
Proactivity: Monitoring is often reactive in nature, alerting teams when predefined thresholds are exceeded or issues occur. In contrast, the other is more proactive, providing real-time insights into the behavior and allowing teams to address issues before they impact end users.
Scope: Monitoring typically focuses on individual components of a system, such as servers, databases, or applications. In contrast, observability provides a more comprehensive view of the entire system, including interactions between components and how they impact system behavior.
Flexibility: Monitoring tools are often designed to collect predefined metrics and logs, making it difficult to capture data that may not have been anticipated by companies. In contrast, the other has tools that are designed to be more flexible and extensible, allowing teams to collect and analyze a wide range of data sources.
Complexity: As systems become more complex, monitoring can become less effective at identifying and diagnosing issues. In contrast, observability is designed to be effective in complex systems, providing a more holistic view that can help identify issues that may not be captured previously.
Monitoring infrastructure is very passive and reactive while observability on the other hand is more proactive and goes way deeper than you would be able to go if you only stick with monitoring.
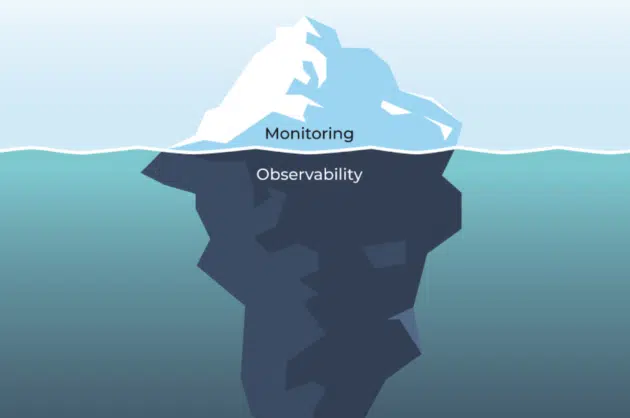
The source link for the image above is here
A much more summarized way to look at it is the image below
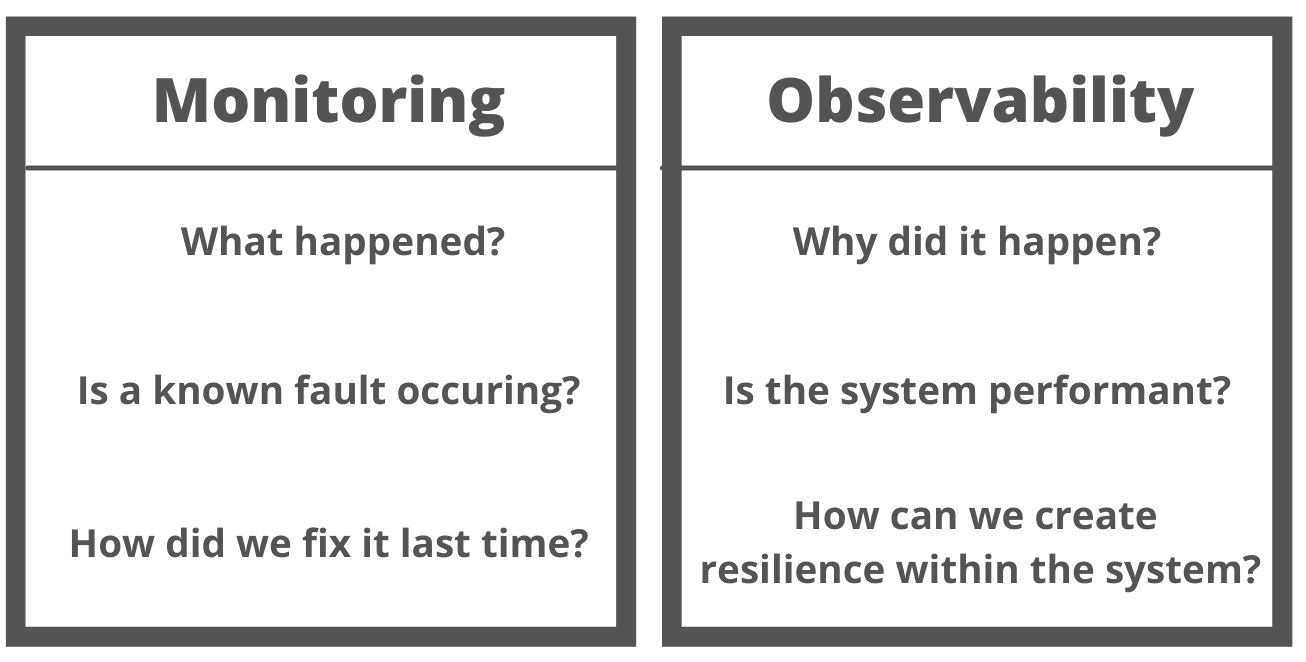
The source link for the image above is here
Why does your business need observability?
Observability can help teams ensure the reliability, performance, and security of complex systems, enabling them to deliver high-quality software applications and services to their users. Tools play a critical role by providing the insights and visibility needed to manage complex systems effectively. By using observability tools, teams can diagnose and address issues more quickly, proactively monitor health and performance, and improve overall system reliability and user experience.
Here are some of the key needs for using observability :
Diagnosing issues: As systems become more complex, it becomes increasingly difficult to identify the root cause of issues when they occur. These tools provide data and insights, allowing developers and operations teams to diagnose and address issues more quickly and effectively.
Proactivity: Observability tools allow teams to monitor the health and performance of systems proactively, rather than reacting to issues as they occur. This can help prevent downtime and other issues that can impact end-users, ensuring a better overall user experience.
Managing distributed systems: Modern solutions are often distributed across multiple servers, data centers, and even clouds. Tools can provide a unified view of system behavior, allowing teams to own these distributed solutions more effectively.
Improving performance: tools can help identify performance bottlenecks and other issues that can impact the speed and responsiveness of applications. By identifying and addressing these issues, teams can improve overall application performance and user experience.
Enhancing security: tools can help identify security vulnerabilities and suspicious activity, allowing teams to proactively address these issues before they can be exploited by attackers.
Compliance: Many industries are subject to regulatory requirements that mandate the use of observability tools to monitor and manage systems. Compliance with these regulations can be achieved more easily and effectively through the use of tools.
Collaboration: tools can provide a shared view of system behavior, allowing teams to collaborate more effectively across departments and organizations. This can help improve communication and coordination, reducing the likelihood of issues and improving overall system reliability.
What is causing the rise in the cost of observability?
Increasing costs are as a result of the increasing complexity of modern systems, as well as the need to collect and analyse large amounts of data in real time. While observability tools are essential for the management and monitoring of complex systems, they can also be costly in terms of personnel, infrastructure, and compliance requirements. As a result, organisations need to carefully evaluate their observability needs and choose tools that are scalable, interoperable, and cost-effective.
Data collection and storage: tools for observability require significant amounts of data to be collected and stored, which can be costly in terms of storage and computing resources because of huge data volumes. In addition, collecting and analyzing large amounts of data can also be time-consuming, leading to an increase in the cost and other associated costs with personnel and infrastructure.
Tool proliferation: The variety of observability tools available in the market has increased significantly in recent years, leading to a proliferation of tools within the company. Managing multiple tools can be challenging and costly, as it requires dedicated personnel and infrastructure to support each tool.
Scalability: As systems grow in size, the scalability of observability tools becomes increasingly important. Scaling observability tools can be costly, requiring additional infrastructure and personnel to support the increased workload.
Integration with existing systems: Integrating observability tools with existing systems and processes can be challenging and costly. This includes integrating with existing tools, as well as with other systems such as ITSM and incident management solutions.
Training and expertise: The complexity of tools requires dedicated personnel with specialized training and expertise to administer and use them effectively. This can be costly in terms of both time and resources, as your company needs to invest in training and hiring personnel with the necessary skills.
Compliance: Many industries are subject to regulatory requirements that mandate the use of observability tools to monitor and manage systems. Compliance with these regulations can be costly, as it requires dedicated resources to ensure that the tools are used effectively and in compliance with regulatory requirements.
Vendor lock-in: The use of proprietary observability tools can result in vendor lock-in, making it difficult to switch to alternative tools or vendors. This can be costly in the long run, as your company may be forced to continue using a tool or vendor that no longer meets their needs or is too expensive.
Best practices to control costs increase of observability
Avoiding the rising costs of observability requires a comprehensive approach that includes selecting cost-effective and scalable tools, developing a comprehensive strategy, investing in training and education, and regularly reviewing and optimising observability practices. By adopting these best practices, organisations can ensure that their observability practices remain effective and cost-efficient, even in the face of increasing scale. I will elaborate on the points listed above in a few words.
Choose tools that are scalable and cost-effective: When choosing observability tools, it’s important to select tools that are scalable and cost-effective. This means choosing tools that can handle the growing scale of your systems, without requiring excessive resources or incurring high costs/observability spend. This includes selecting tools that have a reasonable pricing structure and can be easily integrated with existing systems.
Develop a comprehensive observability strategy: Developing a comprehensive strategy is key to avoiding the rising costs associated with observability. This includes identifying the metrics and data sources that are most important, as well as defining the processes and tools that will be used to collect and analyse that data.
Leverage open-source tools: Open-source tools can be a cost-effective alternative to proprietary tools, as they are often free to use and can be easily customised to meet specific requirements. Additionally, open-source tools often have large communities of users, providing access to a wealth of knowledge and resources.
Consolidate tools: The proliferation of tools within organisations can lead to increased costs. Consolidating tools wherever possible can help reduce these costs, while also improving the overall effectiveness of observability. This means selecting tools that can perform multiple functions, as well as ensuring that tools can be easily integrated with each other.
Invest in training and education: The complexity of tooling requires dedicated personnel with specialised training and expertise. Investing in training and education for tooling can help reduce costs associated with tool mismanagement or errors, while also improving the overall effectiveness of observability within an organisation, thus staying better acquainted with the pain points of your customers.
Implement automation: Automating processes wherever possible can help reduce costs and improve the overall effectiveness of observability. This includes automating data collection and analysis, as well as automating incident response and remediation.
Regularly review and optimise practices: Regularly reviewing and optimising practices is important to ensure that costs remain under control and that observability practices are effective. This includes reviewing metrics and data sources, as well as reviewing the effectiveness of tools and processes.
Consider observability-as-a-service: Observability-as-a-service is an increasingly popular option for organisations looking to reduce costs and simplify their observability practices and is easy to integrate with cloud-native apps. Observability-as-a-service providers offer managed observability services, handling the collection and analysis of data, as well as incident response and remediation. This can be a cost-effective alternative to building and maintaining observability infrastructure in-house.
Other Best practices worth considering
Know your Telemetry Data
What are telemetry data that cannot be discarded? If your program for observability is mature, it should allow for the detection of what data are useful to us and why. There are an increasing number and types of third-party consultants that can help you understand how you can avoid certain types of information as well as tell what your observability data is.
Reduce your data Observability cost by 10x using Middleware
Middleware only transmits needed information and can save customers’ personal data in the cloud storage when required to save up to 10x data expenses. Using data can improve your computer’s performance, minimise downtime, and most importantly, offer a better experience for customers.
Reduce the need for multiple tools
Using a central system to administer your application is a great way to get a holistic view. It’s important particularly in a safety incident due to its possibility to occur at any part of the system. You will quickly find out what’s wrong and take action if that’s what’s causing a negative effect.
 Security in cloud native
Security in cloud native
 DevOps and Artificial intelligence - how a DevOps team take advantage of AI and ML
DevOps and Artificial intelligence - how a DevOps team take advantage of AI and ML
 Identity and Access Management best practices
Identity and Access Management best practices