
The field of DevOps, the overall culture, and practices keep evolving really fast. The evidence of this is that there are new tools being built and shipped by the day, we could even say by the hour. This is due to the fact that what works for organization A might not work for organization B. This is in fact what is expected. There is no single way of applying DevOps practices within an organization. There are several use cases and the practical thing to do is to adopt practices that work well for you and your team so long as it aids faster delivery of software products and implementing user feedback while reducing downtime. This evolution has introduced terms like DevOps, DevSecops and until recently GitOps. If you're unfamiliar with the terms mentioned earlier, DevOps eradicates the boundaries between developers and operations in order to make the development lifecycle more agile. DevSecOps on the other hand addresses security vulnerabilities while leveraging automation. We would be diving deeper into this in a future post but for now, let's focus on the third "GitOps".
What is GitOps
GitOps introduces a new way of implementing Continuous Deployment for cloud-native applications. It enables developers to leverage the tools that they are already familiar with, like version control (git), and CI/CD tooling in order to achieve infrastructure automation. It offers an experience that is more developer-centric.
GitOps upholds the principle that Git is the only source of truth for the infrastructure. This means that at any given time, the desired state of the infrastructure needs to be stored in version control such that anyone can view all of the changes that have been applied. All changes to the desired state are fully traceable via committer information like commit IDs, and time stamps. This essentially means that the application and infrastructure are now versioned artifacts that can easily be audited.
GitOps is based on a Git-based source code management system and hence GitHub, GitLab, and Bitbucket are natural choices.
The core idea of GitOps is to have a repository that always contains declarative descriptions of the infrastructure’s desired state or cluster state and an automated process to make the appropriate environment(whether dev, test, or prod) match the described state in the Git repository. If you want to introduce any change to the application or infrastructure, you only need to make this change in the repository and this will trigger an automated process that handles everything else. There are several tools that allow you to achieve this but the most popular gitops tool out there at the moment is argo cd. There are other popular gitops tools like Flux, Jenkins X, Harness, Weaveworks, JFrog, and lots more.
GitOps requires three components - IaC, Merge requests & CI/CD.
The way this is implemented by your team is highly dependent on what works best for you. There is no one size fits all approach to how you adopt this within your team.
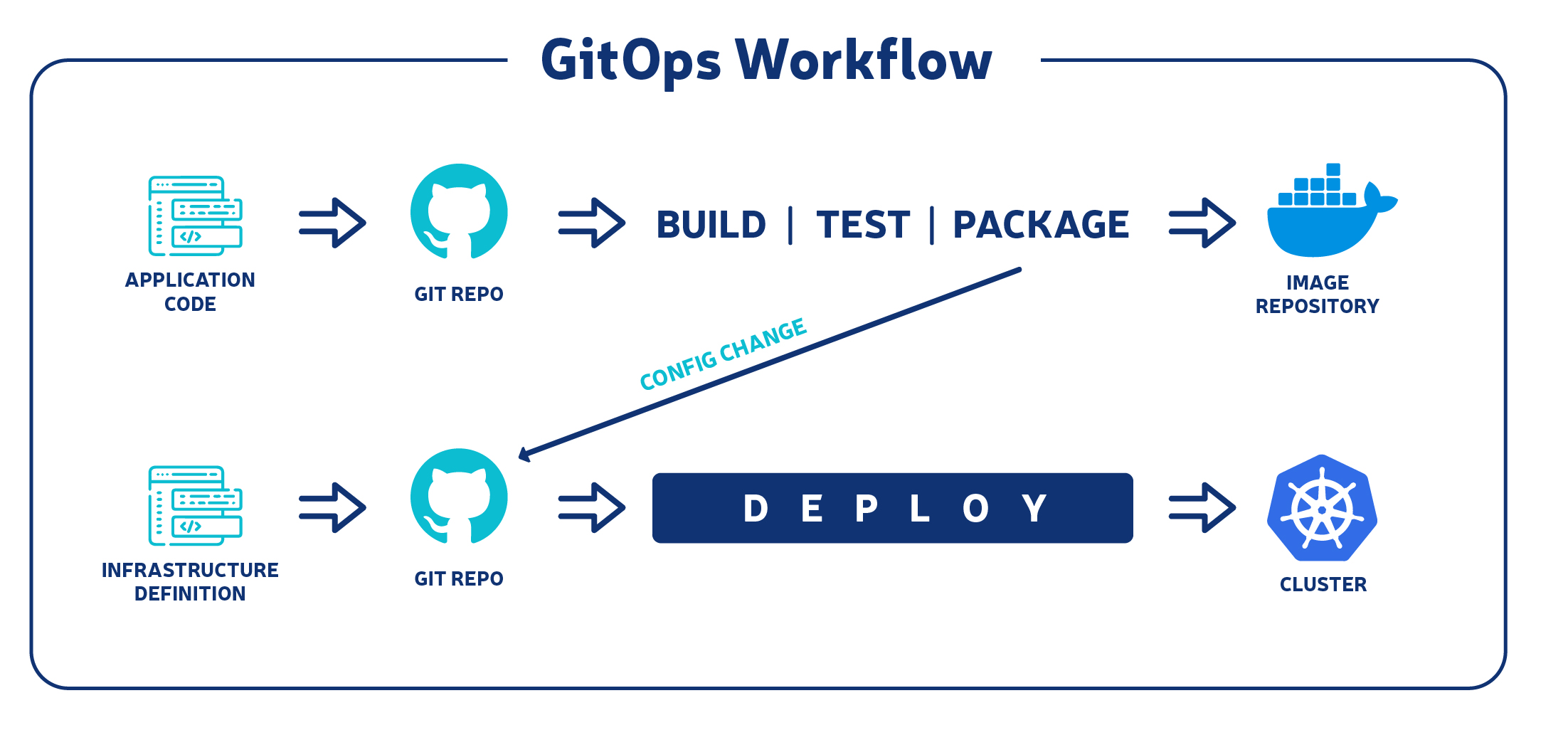
A typical gitops workflow should look like the flow in the image below
Core principles of GitOps workflow
- The entire system needs to be written declaratively.
- The desired state of the system needs to be stored in a version control system.
- Updates have to be done and made MR to be reviewed and approved.
- After changes are approved, there has to be an automatic sync between the actual system and the new state that now exists in the git repository.
- Self-healing - any solution you choose needs to be able to reconcile the state of the application against any code that was updated manually.
Difference Between DevOps & GitOps
Both GitOps and DevOps share a lot of the same principles and similar goals. DevOps is all about cultural change that provides a way for development teams and operations teams to collaborate better.
GitOps on the other hand gives you and your team the tools to take DevOps practices, like CI/CD, IaC, and version control, and apply them to infrastructure automation. Developers can continue to push code to the git repo, while operations can put other necessary pieces in place also while using code and git.
Benefits of GitOps workflow
There are many benefits of using GitOps for infrastructure automation. This includes improved efficiency and security, faster deployments, and lots more but let us dive into a few of them.
Increased productivity & Faster development
With Gitops Continuous deployment automation, you can speed up your MTTD(mean time to deployment). Your development team can ship more than 40 times more changes each day and increase overall development output. Since developers use tools that they are already familiar with, like Git to manage feature updates and new versions in a more rapid manner, this makes development faster. Developers do not necessarily need to know the inner workings of a Kubernetes cluster. They get to focus more on the code being pushed to git which is the single source rather than containers. This makes it even easier to onboard new engineers to the team and have them achieve results in days rather than months.
Increased reliability
Git gives us the capability to revert to older states and this ensures that rollbacks are more stable and easily reproducible. In the case that a member of the team introduces a manual change that breaks the system, it is easier to revert back to the desired state. Again, this gives a better developer experience and makes complex tasks such as disaster recovery less stressful. It’s easier to redeploy your entire system to an entirely different region and even an entirely different cloud provider.
Improved audit & compliance
Using the Git workflow to manage Kubernetes clusters introduces a much more convenient audit log of changes that happened outside Kubernetes. This includes logs like who triggered the change, what was changed as well as a timestamp to know exactly when this change was done to your cluster. This allows you to SOC 2 compliance.
Improved Consistency
Since Git is the single source of truth and entry to every change for both apps and infrastructure, you get a more consistent end-to-end workflow across your team. Not only are your continuous integration and continuous deployment (CI/CD) pipelines all driven by pull requests, but your operations tasks are also fully reproducible through Git.
Stronger security
Git’s strong correctness and security guarantees, and the strong cryptography used to handle changes ensure that there is a secure definition of the desired state of the system. This along with the automated reviews of each step of the change makes GitOps a great way to secure the delivery pipelines. In the event that there is any security breach, it is easier to audit and track. Reproducing this insecure system independently for a better understanding of the issue is easier and allows a better/faster incident response.
Better ops
GitOps offers a complete end-to-end pipeline. All CI/CD pipelines are driven by pull requests, while every other operations task can still be achieved through Git by committing updates to the particular git repository.
Challenges of GitOps
Before adopting this new trendy workflow, there are a few things you need to know. There is a high chance that this is not suitable for your team or even the kinds of solutions that you build. As they say, everything that has pros also has cons.
Gitops certainly does introduce changes that help your entire development lifecycle more developer friendly but this also means that the team needs to adopt this new way of working. It is a change that requires discipline and commitment from everyone on board. Things need to be done in an entirely new way. A lot more needs to be written down.
A GitOps approval process entails: developers making updates to code on git repositories, creating merge requests, approver merging changes, and then the change is automatically deployed. This sequence introduces a “change by committee” element to infrastructure, which can seem tedious and time-consuming to engineers used to making quick, manual changes.
It is important for everyone on the team to record what’s going on in merge requests and issues. The temptation to edit something directly in production or change something manually is going to be difficult to suppress, but the less “cowboy engineering” there is, the better GitOps will work.
GitOps Demo Project
It’s time to get our hands a little bit dirty. The demo project below will be built using argocd as this is arguably the best gitops tool available in the market at the moment and is very easy to get up and running.
Prerequisites
- Basic understanding of Kubernetes & Docker
- Understanding of git workflow
Tools Needed
- Docker Desktop
- Git repo - I used GitLab for this project and to follow along you would need a public repo for argocd to be able to sync without errors. It is possible to still use a private repo but that requires some additional configurations to be made.
- Minikube - I would be running the demo on my local machine. In the next post, we would look into how to use it with AWS EKS.
- Web Browser - we need to access the argocd GUI which gives us a well-detailed web view of our deployments and cluster setup in general
time for some fun
At this point, I assume that you already have all the tools set up so I will skip the initial setup of all the above-mentioned tools.
The first thing we need to do is to set up argocd on our cluster. To do this, we need to first create a namespace for Argo cd
~ kubectl create namespace argocd
~ kubectl apply -n argocd -f
https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
The two commands above basically create an argocd namespace that holds the services and applications resources we need.
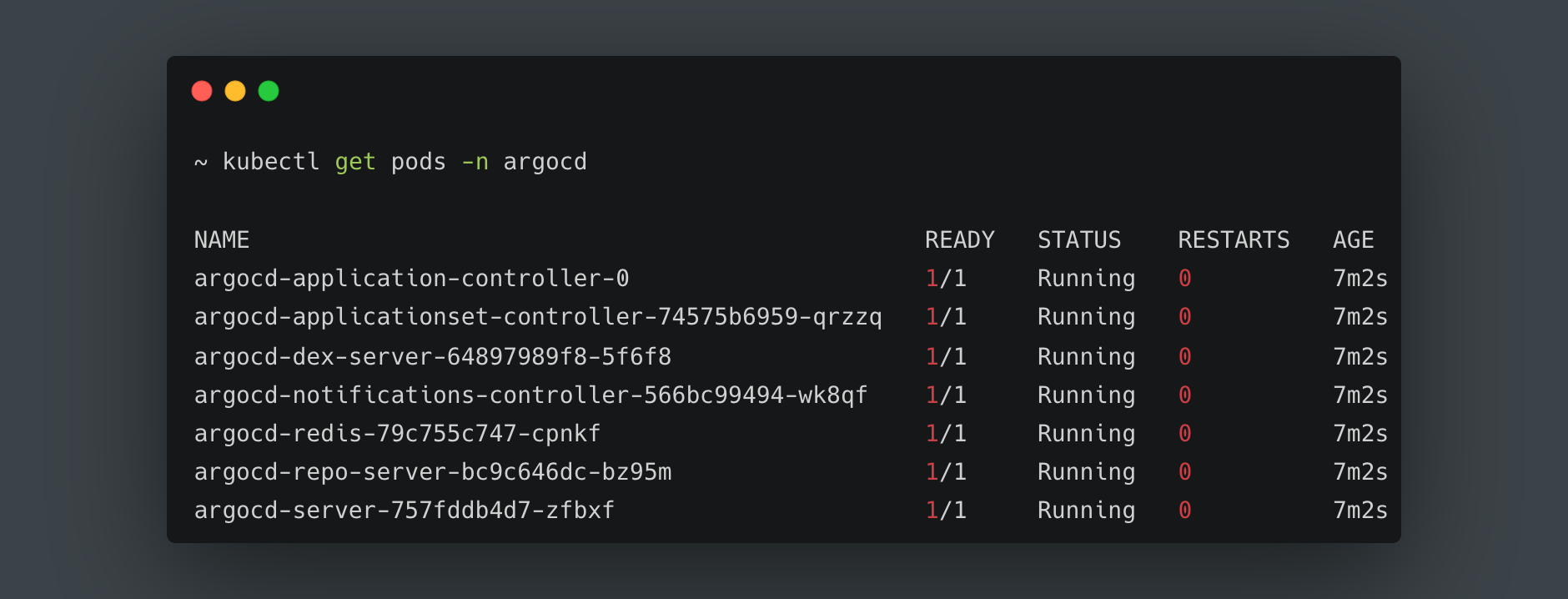
After running the commands above, we should be able to list the running pods using the command below:
kubectl get pods -n argocd
This lists all the pods running in the namespace we created earlier named argocd like the image below:
Let’s try to list the services running.
kubectl get svc -n argocd
The above command will list all the services we have running within the same namespace named argocd. If the output you get looks like the one below, you can access the web UI.
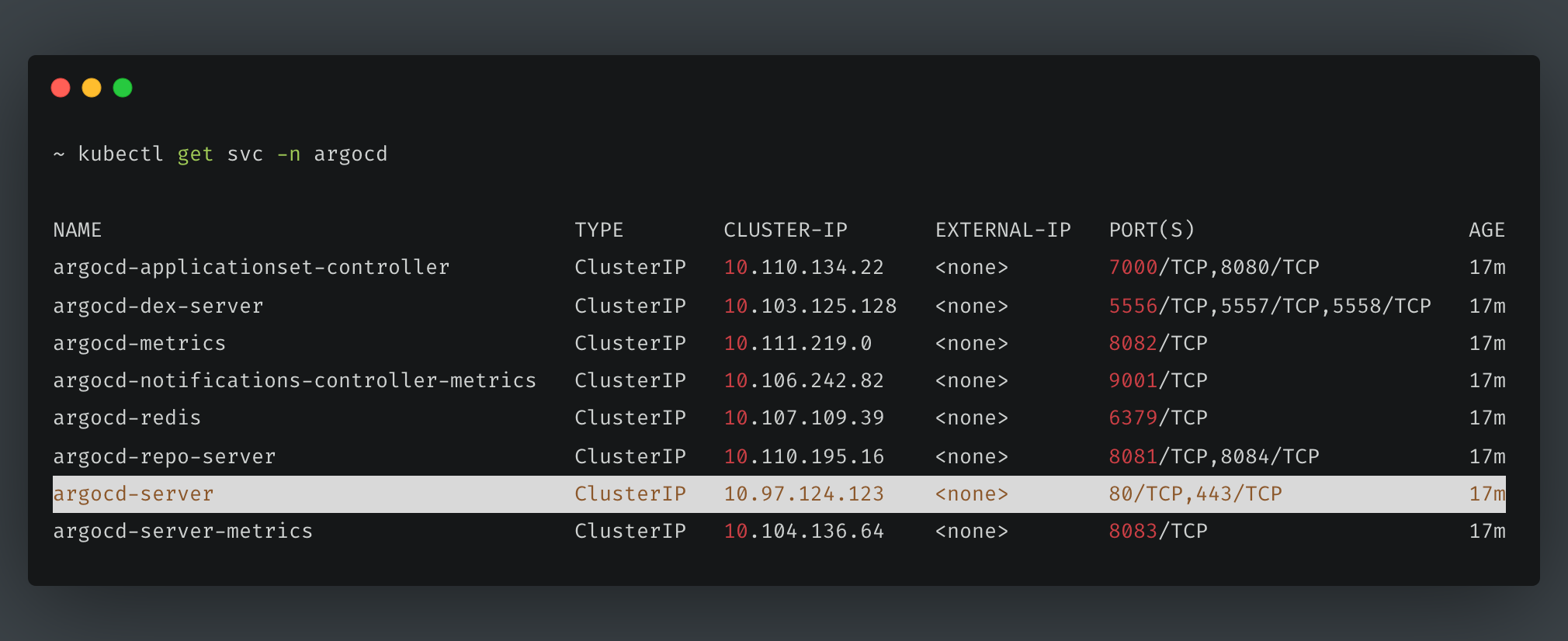
In order to access the web UI, we need to port forward the IP address of the highlighted service to port 8080 on our local machine by running the command below:
kubectl port-forward -n argocd svc/argocd-server 8080:443
This will show you an output with the IP address to access argocd web UI. Copy this address and paste it into your browser. If all is fine, you will be able to see argocd login page like the one below:
You might be wondering what the login details are. This is already set up by default. The username is admin and the password is already added as a secret when you set up argocd and named argocd-initial-admin-secret. To retrieve the secret, simply run the command below:
kubectl get secret argocd-initial-admin-secret -n argocd -o yaml
This will return a YAML output with the password
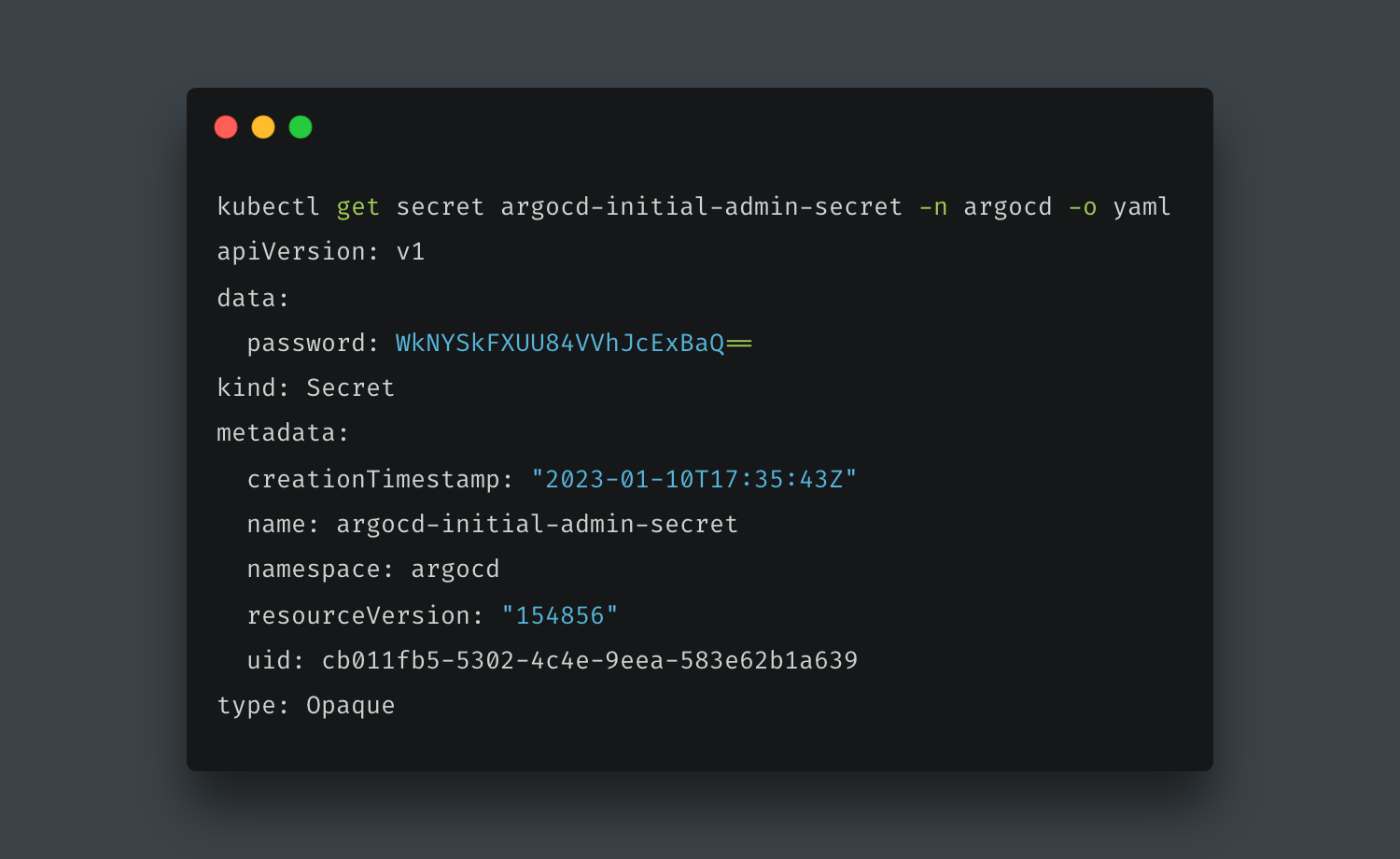
You can get the plain text of the password by running
echo YOUR_PASSWORD | base64 --decode
If you enter in the username and the password, you should be able to log in successfully.
The second thing we need to do is to set up the project and push it to our own git repository. Again I will assume you already know how to do that and just list all we need (file structure).
- Create a directory in the project and give it a name of any environment of your choice. I will name mine development.
- Inside this directory, create two files - deployment.yaml & service.yaml.
For our deployment.yaml, copy and paste the code below:
apiVersion: apps/v1
kind: Deployment
metadata:
name: gitops-demo-app
spec:
selector:
matchLabels:
app: git-ops-app
replicas: 2
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: fessywonder/golang:1.0
ports:
- containerPort: 8080
For our service.yaml, copy and paste the code below:
apiVersion: v1
kind: Service
metadata:
name: myapp-service
spec:
selector:
app: myapp
ports:
- port: 8080
protocol: TCP
targetPort: 8080
We need the files above to set up our cluster and application. But we would also need to set up argocd in our cluster.
Now we need to set up argocd in our cluster. To do this we need to create another file. You can name this app.yaml and paste the code below into it.
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: myargo-application
namespace: argocd
spec:
project: default
source:
repoURL: https://gitlab.com/t9151/gitops-blog-post.git
targetRevision: HEAD
path: dev
destination:
server: https://kubernetes.default.svc
namespace: myapp
syncPolicy:
syncOptions:
- CreateNamespace=true
automated:
selfHeal: true
prune: true
Note: The project needs to be pushed to our single source of truth since we need the URL for the argocd setup in the cluster. The image being referenced on deployment.yaml and the repoURL on app.yaml are both image from a personally owned public image on docker hub and a project on GitLab respectively. So long as I leave this available, it will work, else you can change those and use yours or search from the list of docker images on docker hub and any. You can also clone the repo and not have to create yours.
At this point, we are ready to apply and have our application and its resources created. You can do this by running the command below:
kubectl apply -f app.yaml
You will get an output that your application has been created and if you go back to the argocd UI you will be able to see the below
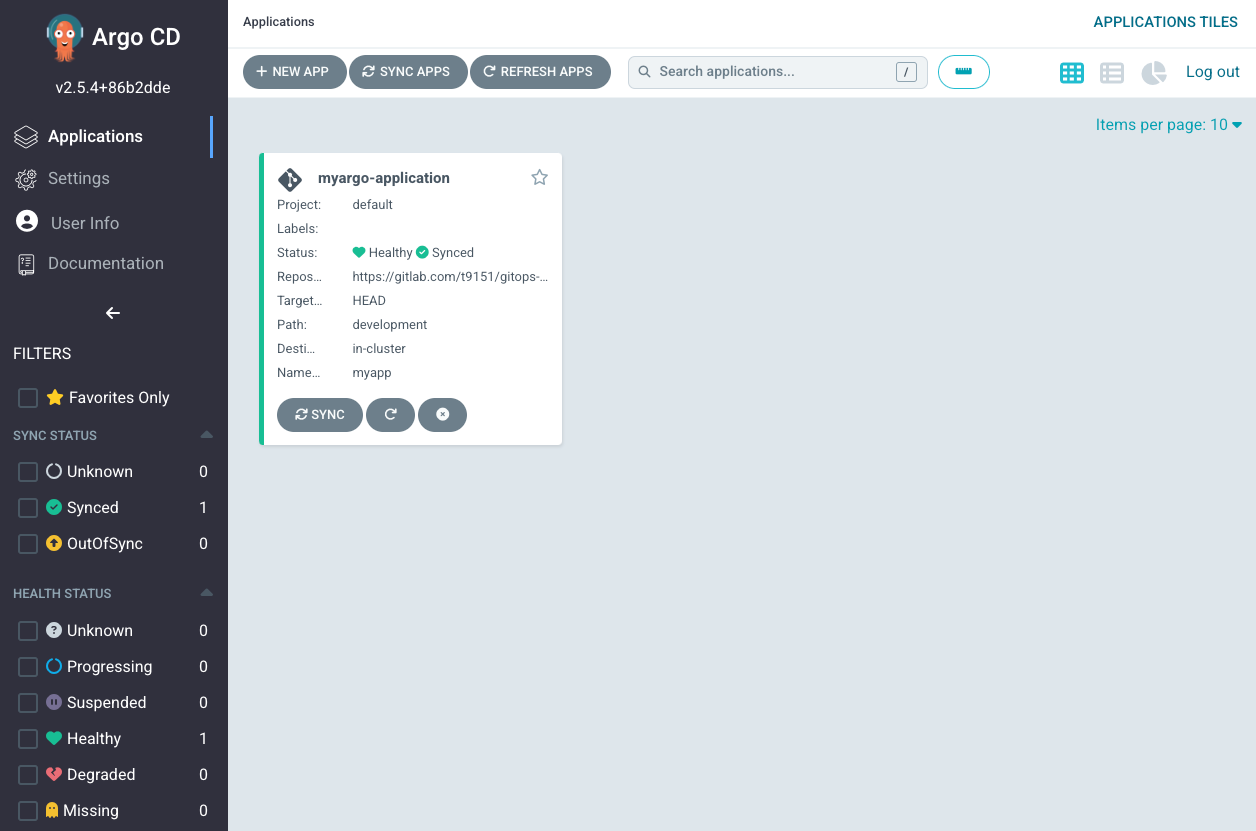
The image being used is just a golang official image and it does not have several components.
In order to see argocd/gitops in action, change something on either of the files (like the app name), commit, and push to the git repository. Argo cd has self-healing provided for us to enable as can be seen in our setup file. It is able to perform status checks/health checks and tell us when something has gone wrong. Argo cd will spot this change within 3 minutes and the update will be done. You will see the sync status, the commit details, and the time it was done. Also if you manually override the deployment on your local machine, for some seconds argo will deeply the change you applied and roll back to the state that exists on the repository.
 What is DevOps?
What is DevOps?
 DevOps vs SysOps - similarities and differences
DevOps vs SysOps - similarities and differences
 Security in cloud native
Security in cloud native